I decided to do it. I bought myself a PC tower so that I could run LLMs locally and have enough processing power that it wouldn’t take me three minutes per query. I vetted some specs with a couple gents in my AI content community and then bought myself a gaming PC with a NIVIDA GeForce RTX 4070 Ti graphics card. I did forget I was going to need a non-Apple mouse and it took me four attempts to find one in my box of “computer bits,” but hey, the fancy ergonomic one my sister gave me three years ago for Christmas works great!
While I have a number of AI related projects I want to attempt, I decided to keep things simple by trying to reverse engineer the Mac app, Keep It Shot, but run it on Windows. Ha. Am I being ambitious? Maybe. But in theory, AI is supposed to make this easier and I can be very tenacious once I have an objective.
Aside
During my college years, I accidentally bricked my laptop for a very stressful thirty-six hours wherein a virus prevented me from opening almost every application on my desktop. However, as a student in web design who needed to do cross-browser testing before cross-browser testing tools existed, I had all the browsers. And bless them, Mozilla Firefox was the only browser not affected, so I read a lot of forums, found myself a kill script, and ran it through terminal. Did I know what I was doing? No. But I was very motivated.
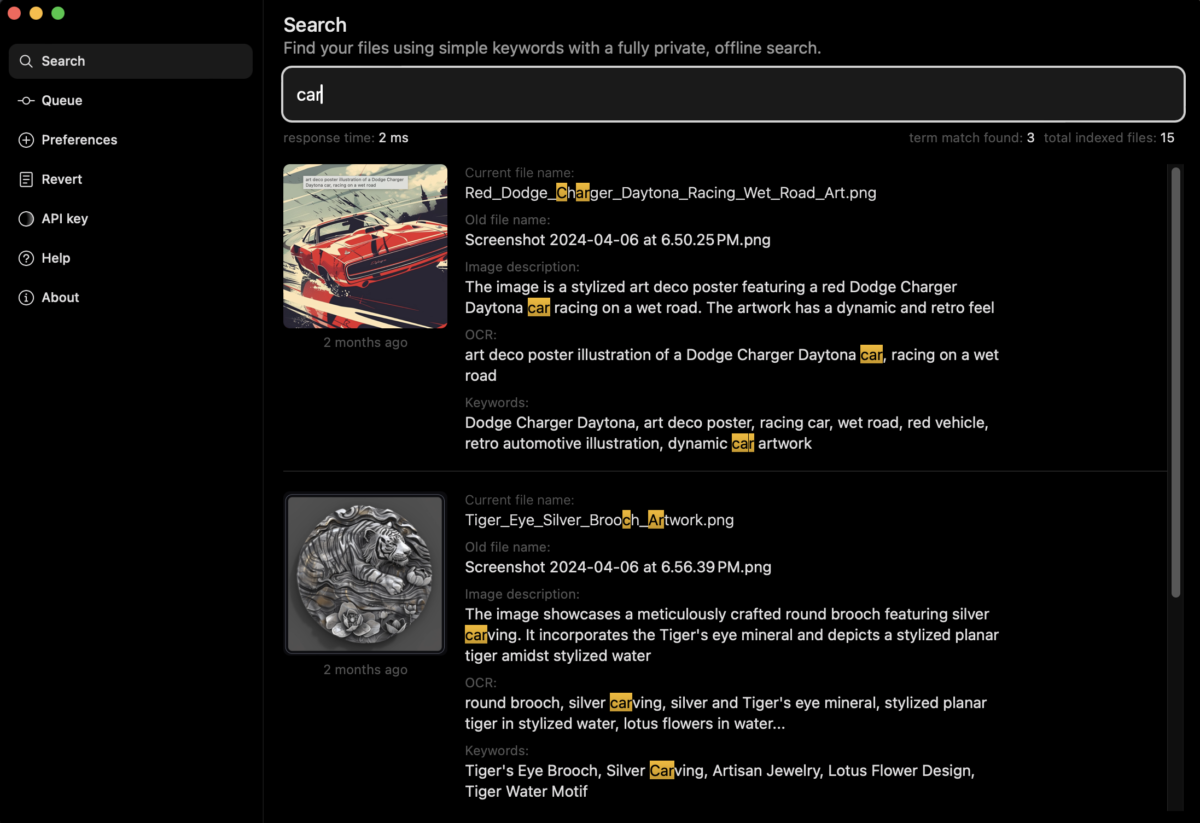
Do I know what I am doing now? Sorta. I understand the foundational elements involved: 1) image captioning LLM for object detection, 2) script to rename files, and 3) desktop app to search by image file name and description by keyword, but the rest is – as they say in scrum planning – “implementation details.” I’ve decided to break my implementation out into phases and much like I do with complex product design work, I’m starting with text pathways – enumerating task steps and documenting any open questions.
Prerequisites
- Install VSCode on PC
- Connect image folder on network to access images on both Mac & PC, so that I can apply this process to my folder of Midjourney images.
- Install shell commands VSCode and Continue.dev plugin for chatting with LLM
- Download Ollama & Qwen on Windows for Continue.dev
Phase 1
Use an image captioning model to perform object detection on a batch of image files and output a list of descriptor words per file
Process Steps
- Select directory
- Iterate through each image by unique ID
- Analyze image with image captioning model
- Q: Are there open-source image captioning models? Will they need fine tuning? Or should I use the OpenAI Vision model? What is the cost of API calls?
- Output: Print current file name, then print list of descriptors.
- Q: How are descriptors determined? Is object identification nouns or can it describes styles / adjectives?
- Q: What should max number of descriptors be?
Phase 2
Rename files based on their text captions via script or automation workflow.
Process Steps
- Loop through each image, edit file, rename
- Rename using descriptors
- Q: How do I avoid cases where existing images have the exact same descriptors?
- Q: How do I weight descriptors so the more relevant ones are at the beginning of the file name?
- Q: Is there a way to use shorter synonyms to avoid hitting 255 character limit on blob input?
- Q: How do I only run this on images that do not already have descriptors in the file name?
- Assign hyphens between words to fill spaces
- Paste full set of descriptors into Tags (Mac) / Details (Window) property on image file
Phase 3
Use a No Code application, such as FlutterFlow, which can be run as desktop app, or a code AI assistant to build simple GUI for searching.
Process Steps
- Select directory
- Search by keyword
- Query iterates through all image files in directory, scanning file names and tags/details for key word
- Results are returned in a list with keyword is highlighted in context and image preview
Build Steps
- Download Flutterflow and determine if database or file path can be attached as source
- If not, use a centralized AI assistant to find a Python GUI framework
- Start laying out a shell interface
How far have I gotten?
While I have accomplished everything in my prerequisite list, I am starting to think I might have gone for the most complicated solution first by trying to find an open-source image captioning model. There are multiple scripts – no AI needed – that rename images based on the keywords embedded in the PNG file format. Additionally, the image captioning models appear to need some fine tuning, which is a process I don’t fully yet understand. I’ve installed both LM Studio and Jan.ai to experiment with local conversational AI, but I’m not sure if the image captioning models could be used in the same interface. At the same time, it looks like the OpenAI API might allow limited free calls or at the very least, very, very cheap calls, so given that I know Keep It Shot is using them as their object detection model, I decided I might want to start there.
My baby steps forward have gotten me an OpenAI API key and a GitHub repo with a script for renaming image files. I had to take a brief detour to install Python globally as apparently the error I was receiving in Power Shell while trying to run the script was because I didn’t the PIP manager installed. But thanks to the AI Code Assistant I had installed, which was leaning on Ollama – so apparently I do have Python installed somewhere, I was able to remediate my errors without having to wade through Stack Overflow. I still haven’t actually converted an image to text descriptors yet, but that’s partially because I was fighting with keybindings in VSCode for entirely too long. (I absolutely need to be able to use Ctrl + V, Ctrl + S, and Ctrl + Z, but these are apparently mapped to other functions in the Windows version of the IDE.) All in all, it’s still 100% a learning process, but I’m having fun.